
Repair of DNA Damage
The chapter on Mutation discussed some of the ways that DNA could be damaged and the types of mutations that could result from each type of lesion. But as mentioned at the end of the chapter on mutation, not all DNA lesions result in mutation. Cells have numerous repair mechanisms in place to fix damage as it occurs, and the (im)balance between damage and repair is what results in accumulation of mutations.
DNA damage can occur as a result of normal cellular processes: metabolic byproducts damage DNA, as can the act of replication. But DNA damage can also be a result of exposure to exogenous mutagens, environmental agents like chemicals or radiation that damage DNA. Anything that increases the rate of DNA damage tends to also increase the possibility of cancer, since it shifts that balance toward damage rather than repair.
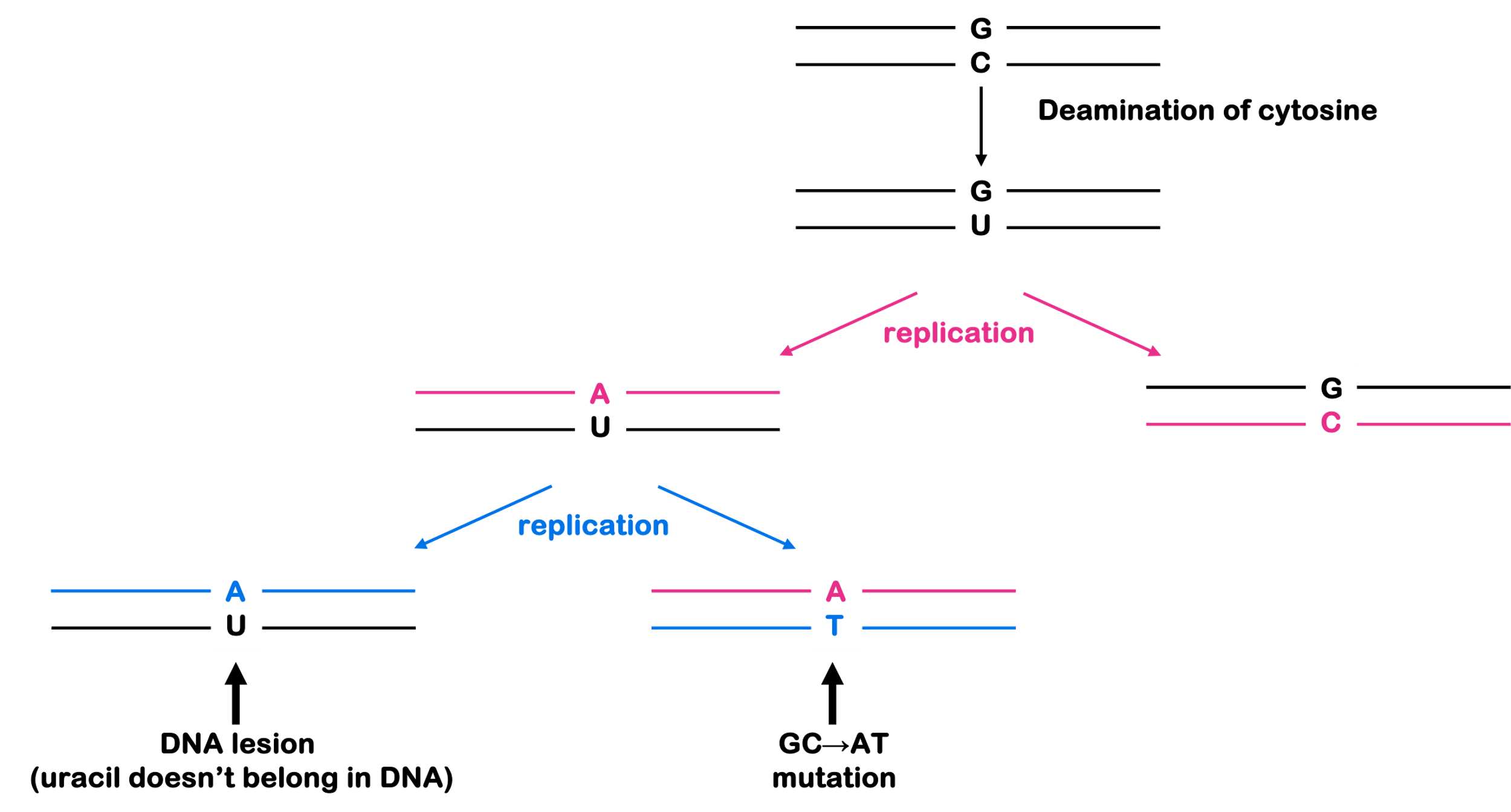
Most DNA repair processes detect DNA lesions due to their effect on the overall shape of the DNA double helix: lesions disrupt the nice, even helical structure of the molecule. The goal is to repair the DNA before it is replicated or distributed to daughter cells during mitosis. If a lesion is used as a template for replication, the resulting daughter may have the wrong complementary base installed. And if that strand is used as a template for replication, the result is a perfect double helix that can’t be recognized by DNA repair proteins. Now, the cell usually cannot tell what the original base should have been and can no longer deploy repair mechanisms. It is at this point a lesion becomes a mutation.
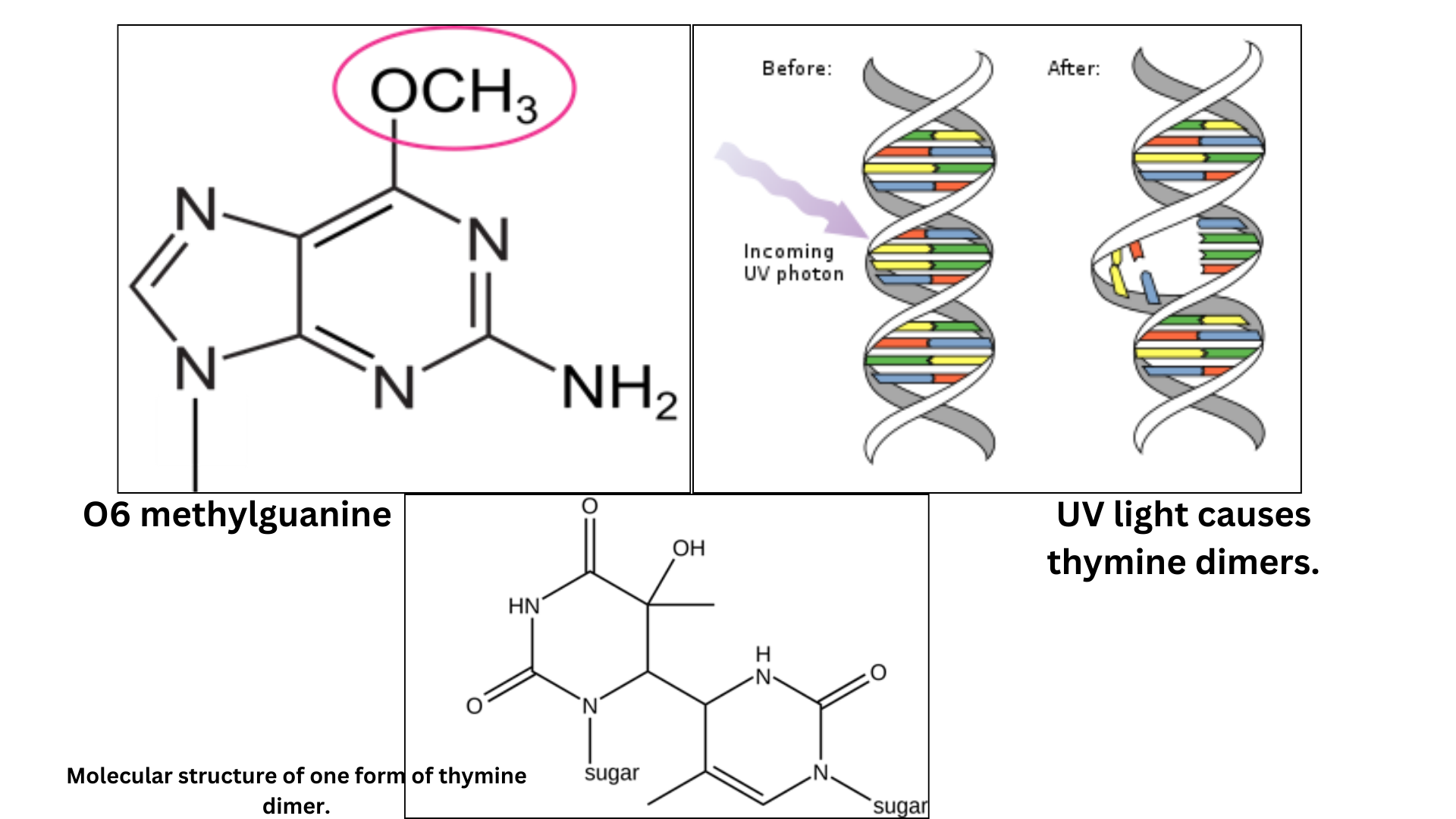
There are a few methods by which cells can directly reverse DNA damage. One is dealkylation, which removes alkyl groups like —CH3 or —C2H5 from alkylated bases. The alkyl group is directly transferred to the protein O6-alkylguanyl-DNA alkyltransferase. A second example of direct reversal are the photolyases, which can undo the linkage between pyrimidine dimers. Pyrimidine dimers are caused by exposure to UV light, and these enzymes use the energy from light to catalyze the repair reaction. This is called photoreactivation. These lesions are shown in Figure 5. Photolyases are used by many organisms from bacteria to eukaryotes, but they are not found in humans or other mammals.
But most other forms of DNA repair do not directly reverse the chemical damage to DNA. Instead, they fix lesions indirectly by performing a similar series of steps:
- Detection of the DNA lesion
- Excision (removal) of the damaged part of the chromosome
- Use of an undamaged strand as a template to synthesize replacement DNA
- Ligation of old with new DNA
The enzymes involved in this process depend on the type of lesion.
- Damaged bases are repaired via base excision repair (BER)
- Larger DNA lesions affecting multiple nucleotides are repaired via nucleotide excision repair (NER)
- Mismatches in DNA caused by replication errors are repaired by the mismatch repair pathway
- Double-strand breaks are repaired via homologous recombination or non-homologous end joining
Each pathway includes a family of proteins that work together to perform these same basic steps of the repair process.
Test Your Understanding
Base Excision repair
Base excision repair recognizes and removes small lesions to single bases. This repair can include deaminated bases (like the conversion of cytosine to uracil), oxidative damage to bases (which happens as a result of normal cell metabolism and exposure to oxidative chemicals), or other damaged bases.
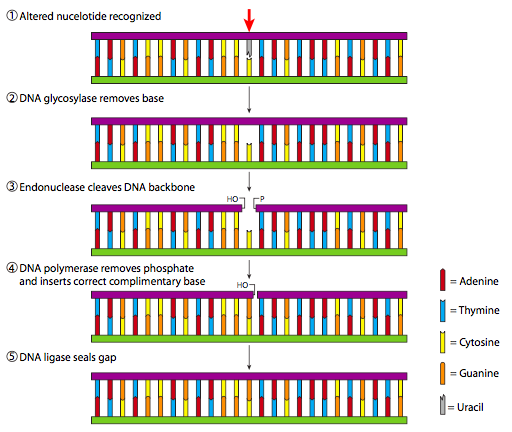
Base excision repair uses a family of enzymes called glycosylases to remove the damaged base. Glycosylases typically recognize a specific base: for example, there are uracil glycosylases that would repair the lesions shown in Figure 4 (uracil never belongs in DNA). The removal of the damaged base leaves behind an abasic site (missing a base). The abasic nucleotide is cut out of the DNA with an endonuclease, a DNA polymerase fills in the gap, and the nick is sealed with ligase. This process is shown in Figure 6.
Nucleotide Excision Repair
If the DNA lesion is bulky or involves more than one base, nucleotide excision repair is used instead. In the absence of photolyases in mammals, nucleotide excision repair is used for pyrimidine dimers and other larger lesions to the bases.
In eukaryotes, many of the proteins involved in this process belong to the XP family of proteins, shown in Figure 7.
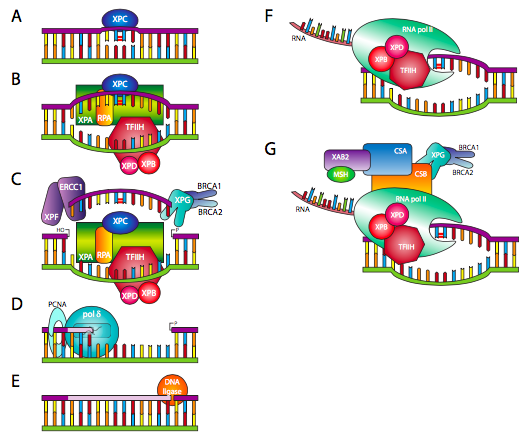
The XP family of proteins is named for the genetic disease Xeroderma Pigmentosum (or XP for short). XP is an autosomal recessive disorder that causes extreme sensitivity to UV light – even just a few minutes of exposure to sunlight results in severe sunburns. People with XP are up to 10,000 times more likely to develop skin cancer than the general population (that’s right, 4 zeros). This likelihood of skin cancer comes about because they have a loss of function variants in the XP genes and they cannot repair the damage caused by UV light.
This explanation gives you an idea of how frequently healthy XP proteins work to repair DNA. Most people can withstand more than a few minutes of sunlight because their cells can keep up with the repair.
Mismatch Repair
Mismatch repair recognizes mismatched bases in DNA and other replication errors. Mismatches occur during replication due to the misincorporation of bases. In the chapter on Mutation, we discussed how this can happen due to the tautomeric shifts of the bases, which can affect base pairing properties.
In prokaryotes, enzymes called MutS and MutL recognize the “kink” in the DNA caused by a mismatch. Additional proteins bind to the protein complex and remove part of the daughter strand around the mismatch. A DNA polymerase then synthesizes new DNA across the gap, and ligase seals the nick in the backbone. This process is shown in Figure 8.
How does the cell know which is parent and which is a daughter? In prokaryotes, DNA is methylated at particular sites in the genome, usually on both strands of the double helix. But immediately after replication, the new strand still needs to be methylated. You can see this in Figure 8, where the green oval representing a methyl group is only seen on the top strand. The daughter strand is the one without methyl groups. Mismatch repair doesn’t work for more than a few minutes after replication, because after that both strands of the double helix are methylated.
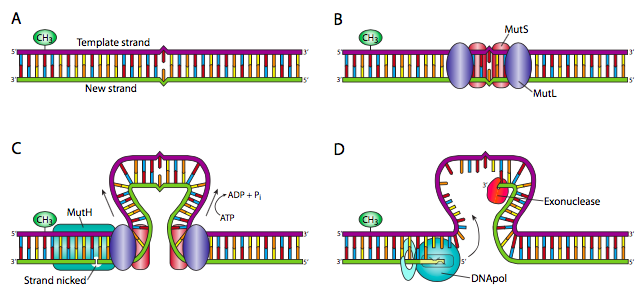
There is no methylation to mark the parent strand in eukaryotes. Instead, eukaryotes use a similar mechanism but detect the daughter strand by the presence of Okazaki fragments. Again, the process must be completed within minutes of replication since the lagging strands are ligated together very quickly after replication.
In eukaryotes, there are families of homologous proteins to MutS and MutL called MSH (for MutS Homolog) and MLH (for MutL Homolog).
In humans, the MSH and MLH family of proteins are associated with Lynch syndrome, a form of hereditary colorectal cancer. MSH and MLH mutations are also associated with microsatellite instability, which is the expansion or shrinkage of short repeated elements in the genome. These are also replicative errors.
Double-strand break repair
Some of the most damaging lesions to the cell are double-strand breaks, which are breaks across both strands of the DNA backbone. DNA breaks can be caused by exposure to ionizing radiation (like X-rays) as well as certain kinds of chemicals. Other types of DNA damage can lead to double-strand breaks if they cause the replication fork to get “stuck” during replication.
Unlike the previous lesions in this chapter, double-strand breaks can affect many genes all at once: any part of the chromosome separated from the centromere will not be properly sorted during mitosis or meiosis. Thus, failure of the double-strand break repair pathway can lead to aneuploidies with missing parts of a chromosome. Improper repair of breaks also contributes to translocations and inversions.
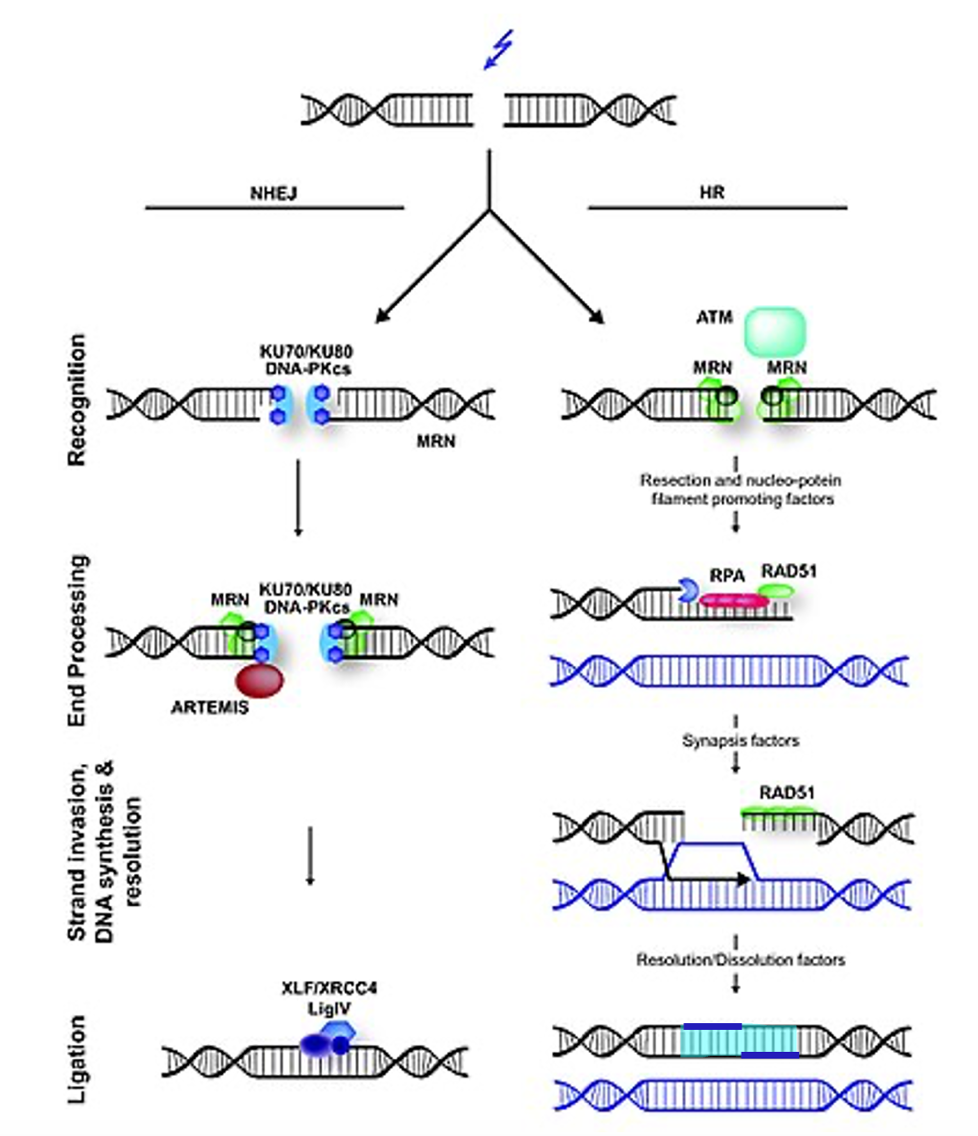
A double-strand break, shown at the top of Figure 9, can be repaired via one of two mechanisms: Non-homologous end-joining (NHEJ) or homology-directed repair (HR).
Non-homologous end-joining (shown on the left) is pretty much exactly what it sounds like. NHEJ proteins recognize the break, recruit additional proteins to trim up the end, and a ligase joins the ends back together. But this is an error-prone process. Nucleotides are always lost around the break. So why might a cell choose to repair in a way that is certain to introduce mutations? Remember that the majority of the eukaryotic genome is not a coding sequence. Hence, a loss of a few nucleotides is preferable to the loss of a whole chunk of chromosome.
Homology-directed Repair, on the right in Figure 9, uses many of the same proteins used during homologous recombination (crossing over) in meiosis. In homology-directed repair, the double-strand break is recognized and processed to expose a long single-stranded region of DNA. The single-stranded region is used to search for homology, preferably in a sister chromatid, which should share identical sequence to the broken DNA. When a match is found, the single-stranded region invades the intact double-helix, pushing the second strand out of the way and base pairing with its complement. The intact strands are then used as a template for DNA polymerase to synthesize new DNA across the gap. DNA ligase seals nicks in the backbone, and then the crossovers are resolved, or cut apart. In bacteria, RecA is the major recombinase involved in strand invasion, and RecBCD participates in later steps. In eukaryotes, protein complexes like MRN, RPA, Rad51, and other genes participate in homology-directed repair and are linked with cancer phenotypes .
At first glance, this seems like homology-directed repair would be the best choice to repair double-strand breaks. But it’s not without downsides, either. A sister chromatid is only available in the second half of the cell cycle – after DNA synthesis. While a homologous chromosome can be used for homology-directed repair in the G1 phase, this runs the risk of gene conversion if the paternal and maternal chromosomes have different alleles. Gene conversion occurs when a cell or organism starts as heterozygous but ends with two of the same allele. It happens because one allele is used to patch the other. While gene conversion is often not so bad, on rare occasions, gene conversion can lead to tumorigenesis, if a healthy allele of a tumor suppressor is damaged and repaired to match a loss-of-function allele.
Summary of repair mechanisms
Whoa, that’s a lot! Here’s a summary of the types of DNA damage and their repair in eukaryotes.
| Type of lesion | Repair Mechanism | Selected Proteins Involved |
| Damaged base like deamination, oxidative damage | Base excision repair | Glycosylases |
| Large, bulky DNA lesions | Nucleotide excision repair | XP family of proteins |
| Replicative errors | Mismatch repair | MSH, MLH family of proteins |
| Double-strand breaks | Non-homologous end joining
|
MRN, Ku70/80, DNA-PKcs, XRCC4, Ligase IV |
| Double-strand breaks | Homology-directed repair | MRN, Rad51, BRCA1, BRCA2 and others |
Test Your Understanding
Media Attributions
- Figure 4 DNA Repair © Amanda Simons is licensed under a CC BY (Attribution) license
- O6 methylguaninet © Amanda Simons is licensed under a CC BY (Attribution) license
- Figure 6 DNA Repair © Molecules and Mechanisms (Wong) is licensed under a CC0 (Creative Commons Zero) license
- Figure 7 DNA Repair © Molecules and Mechanisms (Wong) is licensed under a CC0 (Creative Commons Zero) license
- Figure 8 DNA Repair © Molecules and Mechanisms (Wong) is licensed under a CC0 (Creative Commons Zero) license
- Figure 9 DNA Repair © Modified from: Ingo Schubert, Veit Schubert, Jörg Fuchs is licensed under a CC BY (Attribution) license
